research tech report (1) (PDF)
File information
Title: research tech report
Author: Mikhail Tsvik
This PDF 1.3 document has been generated by Safari / Mac OS X 10.11.5 Quartz PDFContext, and has been sent on pdf-archive.com on 13/06/2016 at 17:18, from IP address 91.122.x.x.
The current document download page has been viewed 512 times.
File size: 1.1 MB (36 pages).
Privacy: public file



File preview
Отчет
13/06/16 18:16
Отчет
Задача
Определить критерии конвертации пользователей, выявить зависимости конвертируемости.
Данные
В качестве исходных данных имелись данные по действиям пользователей за 2 месяца разбитые по дням (01.05-30.06) и
все регистрации пользователей за первый месяц (01.05-31.05). Объемы данных 34ГБ и 74МБ соответственно. Примеры
данных:
Actions Data Frame
USER_ID TIMESTAMP TYPE
683294001
1392727142
715014160
DOCUMENT_TYPE UPDATE OTHER_USER_FRIEND OTHER_USER_ID
2015-05-25 DOCUMENT_DELETED PHOTO_ALBUM
02:10:00
null
null
812038158
2015-05-25 GUEST
19:23:20
null
null
false
260427154
2015-05-25 CREATE_DOCUMENT
11:53:20
USER_MESSAGE
false
false
1718441850
Registration Data Frame
USED_ID
TIMESTAMP
1270248661
2015-05-17 11:40:00
1173602184
2015-05-13 15:43:20
62481419
2015-05-23 20:10:00
Подготовка данных
Данные о регистрации пользователей были разбиты по разным файлам (на каждый день один файл). Далее, для того
чтобы определить порог конвертируемости (порог количества действий пользователя в день/неделю, который
показывает его конвертацию), понадобилось сгенерировать следующие данные: на каждый день регистрации
пользователей смотрится их активность через месяц на протяжении недели (например, для пользователей
зарегистрировавшихся 01.05 смотрится активность спутся 24 дня на протяжении недели: 25.05-31.05). В результате
получилось 217 файлов, на каждый день регстрации (31) по 7 дней активности. Пример выходного файла:
Выходной файл для 1 дня регистрации (01.05) спустя 24 дня (т.е. 1 дня активности из 7, 25.05)
USER_ID TIMESTAMP TYPE
DOCUMENT_TYPE UPDATE OTHER_USER_FRIEND OTHER_USER_ID
1881587348
2015-05-25 CREATE_DOCUMENT USER_MESSAGE
13:00:00
false
true
1722734546
1881587348
2015-05-25 MARK_PHOTO
00:13:20
null
true
1148639005
false
null
812038158
430661138
null
2015-05-25 CREATE_DOCUMENT APP_INVITATION
16:36:40
После этого, была создана результативная таблица, в которой содержалась следующая информация: для каждого
сочетания дня регистрации и дня активности были вычислены количество совершенных действий и уникальных
пользователей. Полученная таблица имеет следующий вид:
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 1 of 36
Отчет
13/06/16 18:16
Result Data Frame
reg_day
act_day
uniq_users
events
01-05
25-05
12477
427926
01-05
26-05
12235
423028
01-05
27-05
12109
429909
Первичный анализ
Первым шагом был анализ последней недели первого месяца активности пользователей. Были отсечены пользователи,
которые никак не сконвертировались, т.е. ни разу не были активны на протяжении последней недели первого месяца.
Таким образом, мы посчитали conversion rate как отношение хоть как-то “сконвертированных” пользователей ко всем
зарегистрированным для каждого дня регистрации. Так же, были добавлены показатели средего количества действий
пользователя за неделю и медиана этой величины. В результате получилась следующая таблица:
Таблица со сводкой данных за последнюю неделю первого месяца активности
reg_day
reg_number
conv_users
mean_actions
actions_median
conv_rate
01-05
99614
23056
128.6734
25
0.2314534
02-05
104573
24343
120.5533
25
0.2327848
03-05
115553
26735
114.3660
26
0.2313657
04-05
107516
25006
116.0208
24
0.2325793
05-05
100640
22707
123.7068
25
0.2256260
Гистограмма, описывающая разницу между зарегистрировавшимимися пользоватедями и оставшимися через
месяц
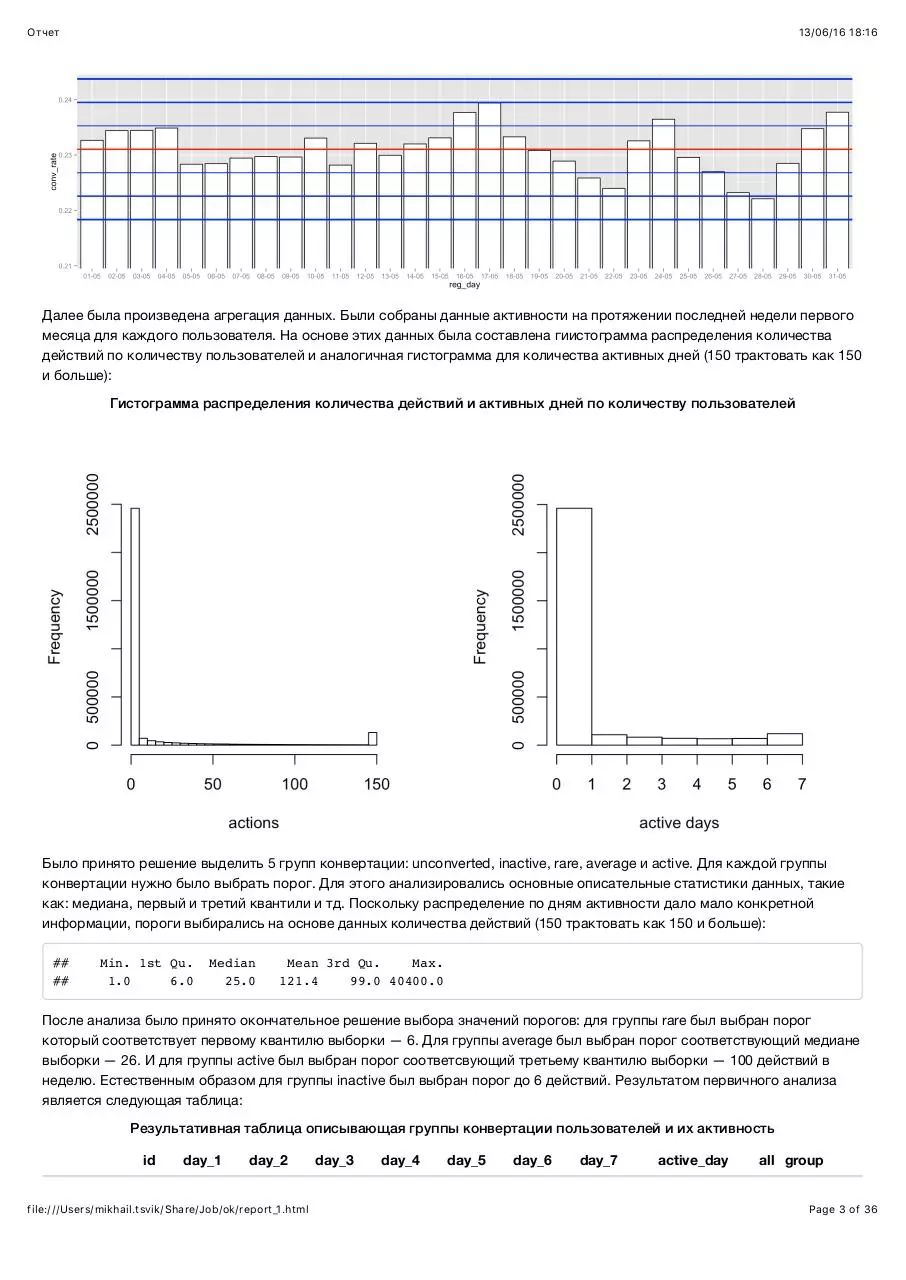
Чтобы выявить аномальные дни, был проведен статистический анализ отклонений conversion rate. Было расчитано
среднее значение и стандартное отклонение conversion rate. Гипотеза состоит в том, что если conversion rate одного из
дней лежит вне пределах трех сигм (3*σ ), такой день считается аномальным и подлежит последующему анализу.
Аномальных дней выявлено не было. Для анализа был построен график с этими показателями (красная линия — среднее
значение, синие линии - стандартное отклонение, сигмы):
Гистограмма, показывающая отклонения от среднего показателя conversion rate
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 2 of 36
Отчет
13/06/16 18:16
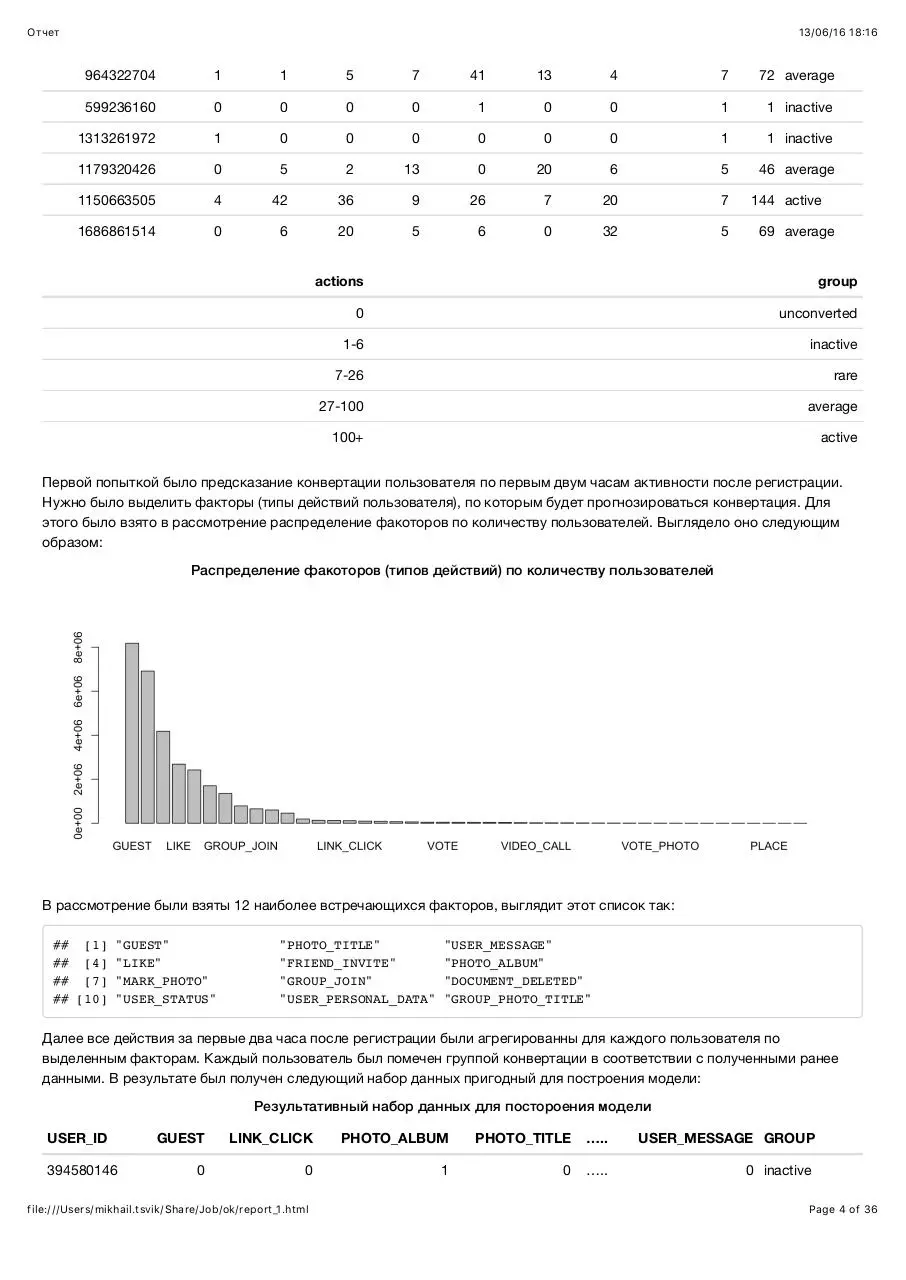
Далее была произведена агрегация данных. Были собраны данные активности на протяжении последней недели первого
месяца для каждого пользователя. На основе этих данных была составлена гиистограмма распределения количества
действий по количеству пользователей и аналогичная гистограмма для количества активных дней (150 трактовать как 150
и больше):
Гистограмма распределения количества действий и активных дней по количеству пользователей
Было принято решение выделить 5 групп конвертации: unconverted, inactive, rare, average и active. Для каждой группы
конвертации нужно было выбрать порог. Для этого анализировались основные описательные статистики данных, такие
как: медиана, первый и третий квантили и тд. Поскольку распределение по дням активности дало мало конкретной
информации, пороги выбирались на основе данных количества действий (150 трактовать как 150 и больше):
##
##
Min. 1st Qu.
1.0
6.0
Median
25.0
Mean 3rd Qu.
Max.
121.4
99.0 40400.0
После анализа было принято окончательное решение выбора значений порогов: для группы rare был выбран порог
который соответствует первому квантилю выборки — 6. Для группы average был выбран порог соответствующий медиане
выборки — 26. И для группы active был выбран порог соответсвующий третьему квантилю выборки — 100 действий в
неделю. Естественным образом для группы inactive был выбран порог до 6 действий. Результатом первичного анализа
является следующая таблица:
Результативная таблица описывающая группы конвертации пользователей и их активность
id
day_1
day_2
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
day_3
day_4
day_5
day_6
day_7
active_day
all group
Page 3 of 36
Отчет
13/06/16 18:16
964322704
1
1
5
7
41
13
4
7
72 average
599236160
0
0
0
0
1
0
0
1
1 inactive
1313261972
1
0
0
0
0
0
0
1
1 inactive
1179320426
0
5
2
13
0
20
6
5
46 average
1150663505
4
42
36
9
26
7
20
7
1686861514
0
6
20
5
6
0
32
5
144 active
69 average
actions
group
0
unconverted
1-6
inactive
7-26
rare
27-100
average
100+
active
Первой попыткой было предсказание конвертации пользователя по первым двум часам активности после регистрации.
Нужно было выделить факторы (типы действий пользователя), по которым будет прогнозироваться конвертация. Для
этого было взято в рассмотрение распределение факоторов по количеству пользователей. Выглядело оно следующим
образом:
Распределение факоторов (типов действий) по количеству пользователей
В рассмотрение были взяты 12 наиболее встречающихся факторов, выглядит этот список так:
## [1]
## [4]
## [7]
## [10]
"GUEST"
"LIKE"
"MARK_PHOTO"
"USER_STATUS"
"PHOTO_TITLE"
"FRIEND_INVITE"
"GROUP_JOIN"
"USER_PERSONAL_DATA"
"USER_MESSAGE"
"PHOTO_ALBUM"
"DOCUMENT_DELETED"
"GROUP_PHOTO_TITLE"
Далее все действия за первые два часа после регистрации были агрегированны для каждого пользователя по
выделенным факторам. Каждый пользователь был помечен группой конвертации в соответствии с полученными ранее
данными. В результате был получен следующий набор данных пригодный для построения модели:
Результативный набор данных для постороения модели
USER_ID
394580146
GUEST
LINK_CLICK
PHOTO_ALBUM
PHOTO_TITLE
…..
USER_MESSAGE GROUP
0
0
1
0
…..
0 inactive
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 4 of 36
Отчет
13/06/16 18:16
1754004182
1
1
1
4
…..
1 unconverted
1045482474
1
0
1
0
…..
0 average
1047107302
0
1
1
0
…..
0 unconverted
Модель
Для анализа была выбрана линейная статистическая модель — логистическая регрессия. Данные были перемешаны и
разделены на две части, 2/3 и 1/3, обучающий и тестовый набор данных соответственно. Модель была построена на
обучающем наборе данных по всем факторам без учета их взаимодействия. С помощью модели была сделана попытка
предсказания группы конвертации для тестового набора данных. Показатели результата применения модели:
AUC, specificity, sensitivity, accuracy
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 5 of 36
Отчет
13/06/16 18:16
Порогом вероятности положительного срабатывания классификатора была выбрана точка пересечения кривых specificity,
sensitivity и accuracy (0.25) как самая оптимальная. Поскольку показатели AUC и Accuracy не дают нам исчерпывающий
ответ о качестве модели (в виду особенностей данных), в качестве целевой функциии были выбраны показатели precision,
recall и F1-мера:
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 6 of 36
Отчет
13/06/16 18:16
test/train
precision — 0.387/0.386
recall
— 0.677/0.678
f1
— 0.492/0.492
Далее модель была применена на обучающем наборе данных. Графики AUC, specificity, sensitivity и accuracy как и
показатели precision, recall и F1-мера не имеют значимых отличий от результатов применения на тестовом наборе данных,
что говорит о возможном недообучении модели. Следующим шагом было усложнение модели, были собраны,
сагрегированны и добавлены данные о действиях пользователей за следующие два часа (2-4 час) после регистрации. На
обновленных данных точно так же была применена логистическая регрессия. Результаты применения:
test/train
precision — 0.403/0.402
recall
— 0.660/0.660
f1
— 0.500/0.500
Модель дала пренебрежимо малый прирост производительности по сравнению с предыдущей. Для дальнейшего анализа
было решено воспользоваться случайным лесом (random forest). Были построены разные вариации моделей: 150000
семплов с 12 факторами (первые 2 часа после регистрации), 300000 семплов с 12 и 24 факторами (первые 2 и
последующие 2 часа после регистрации). Результаты применения случайного леса:
precision —
recall
—
f1
—
150k, 12
test/train
0.541/0.529
0.176/0.172
0.266/0.260
300k, 12
test/train
0.540/0.531
0.186/0.185
0.277/0.274
300k, 12+12
test/train
0.570/0.565
0.223/0.223
0.321/0.320
Можно заметить, что показетели F1-меры заметно ниже, чем у линейной модели. Далее, для улучшения результатов было
решено к случайному лесу применить регуляризацию. Были так же построены разнообразные модели с различными
показателями коэфициентов регуляризации и количества факторов. Результаты применения регуляризации:
precision —
recall
—
f1
—
150k, 12, c = 1
test/train
0.484/0.473
0.246/0.241
0.326/0.319
150k, 12+12, c = 1
test/train
0.501/0.497
0.291/0.294
0.368/0.369
150k, 12+12, c = 0.0001
test/train
0.501/0.496
0.291/0.293
0.368/0.368
Регуляризация дала заметный прирост производительности, но, тем не менее, показатель F1-меры остается низким.
Показатель precision остается на более менее примемлимом уровне, а recall, как с регуляризацией, так и без нее,
находится на очень низком уровне. Это говорит нам о том, что модель имеет высокий false negative rate. В связи с этим,
было принято решение вручную сдвинуть порог принятия решения на более низкое значение для улучшения показателя
recall, и, соответсвенно F1-меры. Эмпирическим путем было подобрано оптимальное значение порога — 0.001. После
введения нового порога показатели recall и F1-мера заметно улучшились, а precision упал в допустимых пределах:
precision —
recall
—
f1
—
regularized random forest
300k, 12+12, c = 1, p = 0.001
test/train
0.425/0.425
0.665/0.657
0.519/0.516
Основные показатели выше, чем у линейной модели, что позволяет нам проводить дальнейший анализ. Далее, после
длительных экспериментов, было принято решение выделить 14 наиболее важных факторов, на основе которых будет
проводиться анализ. По этим факторам была взята информация за первые два и последущие два часа пребывания
пользоваталей на портале. Также в качестве дополнительного фактора был добавлен пол пользователя. По этим
факторам была построена линейная и нелинейная модели (логистическая регрессия и случайный лес деревьев
соотвественно). Итоговый набор факторов:
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 7 of 36
Отчет
13/06/16 18:16
## [1] "PHOTO_ALBUM"
## [4] "GENDER"
## [7] "GROUP_JOIN"
## [10] "LIKE"
## [13] "PHOTO_TITLE"
"GUEST"
"FRIEND_INVITE"
"USER_STATUS"
"SEND_PRESENT"
"DOCUMENT_DELETED"
"USER_PERSONAL_DATA"
"APP_INVITATION"
"USER_MESSAGE"
"MARK_PHOTO"
"RE_SHARE"
Итоговая таблица моделей
После построения моделей можно приступить к изучению значимости переменных (факторов). Будем опираться на
показатель z-value линейной модели и на variable importance случайного леса. Рассмотрим модель с 29 факторами (14
факторов за первые 2 часа активности + 14 за последущие 2 часа + пол пользователя):
## [1] "random forest variables importance"
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
PHOTO_TITLE
GUEST
11684
8528
USER_MESSAGE
FRIEND_INVITE
4127
3548
GUEST_2
USER_STATUS
2995
2269
MARK_PHOTO
GROUP_JOIN
2015
1975
USER_MESSAGE_2
GENDER
1802
1255
PHOTO_TITLE_2
FRIEND_INVITE_2
1106
730
PHOTO_ALBUM_2
GROUP_JOIN_2
623
567
DOCUMENT_DELETED_2 USER_PERSONAL_DATA_2
468
455
APP_INVITATION
RE_SHARE
399
313
SEND_PRESENT_2
RE_SHARE_2
150
60
PHOTO_ALBUM
5430
LIKE
3337
USER_PERSONAL_DATA
2030
DOCUMENT_DELETED
1906
LIKE_2
1139
USER_STATUS_2
660
MARK_PHOTO_2
483
SEND_PRESENT
429
APP_INVITATION_2
161
## [1] "logistic regression variables importance"
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 8 of 36
Отчет
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
13/06/16 18:16
PHOTO_ALBUM
GUEST
100
39
GENDER2
FRIEND_INVITE
29
24
GUEST_2
GROUP_JOIN
17
14
APP_INVITATION USER_PERSONAL_DATA_2
11
11
FRIEND_INVITE_2
LIKE
9
8
USER_MESSAGE
APP_INVITATION_2
8
7
SEND_PRESENT
PHOTO_TITLE
5
5
DOCUMENT_DELETED
MARK_PHOTO
3
3
USER_MESSAGE_2
MARK_PHOTO_2
0
0
RE_SHARE_2
RE_SHARE
-5
-7
USER_PERSONAL_DATA
29
PHOTO_ALBUM_2
23
USER_STATUS
12
LIKE_2
10
GROUP_JOIN_2
8
USER_STATUS_2
6
SEND_PRESENT_2
4
DOCUMENT_DELETED_2
1
PHOTO_TITLE_2
-2
Логистическая регрессия дает представление об общей значимости факторов, линейной, она не учитывает их
взаимодействие. Случайный лес дает представление о значимости с учетом взаимодействий факторов между собой.
Сравнивая значимость факторов линейной и нелинейной модели, можно заключить, что факторы PHOTO_TITLE,
USER_MESSAGE, LIKE и MARK_PHOTO не имеют особой значимости по отдельности, но нелинейная модель говорит о
том, что эти факторы становятся значимыми вступая во взаимодействие с другими. После анализа взаимодействий этих
факторов с другими, были выяалены следущие зависимости, представленные на графиках ниже:
Выявленные зависимости переменных
file:///Users/mikhail.tsvik/Share/Job/ok/report_1.html
Page 9 of 36
Download research tech report (1)
research tech report (1).pdf (PDF, 1.1 MB)
Download PDF
Share this file on social networks
Link to this page
Permanent link
Use the permanent link to the download page to share your document on Facebook, Twitter, LinkedIn, or directly with a contact by e-Mail, Messenger, Whatsapp, Line..
Short link
Use the short link to share your document on Twitter or by text message (SMS)
HTML Code
Copy the following HTML code to share your document on a Website or Blog
QR Code to this page

This file has been shared publicly by a user of PDF Archive.
Document ID: 0000385933.